Ollama 사용 가이드 - 외부 API 버전
시작 전 확인사항
이 가이드를 따라하기 위해 아래 항목이 준비되어 있어야 합니다.
| 항목 | 설명 |
|---|---|
| Gcube 계정 | gcube.ai 회원가입 필요 |
| 크레딧 잔액 | Gcube 플랫폼 이용 시 GPU 사용 비용 발생 (시간 단위 과금) |
개요
Ollama란?
Ollama는 로컬 환경에서 오픈소스 AI 언어 모델을 다운로드하고 실행할 수 있게 해주는 플랫폼입니다. 이 가이드에서는 Gcube 클라우드 GPU 환경 위에서 Ollama를 실행하고, DeepSeek 모델을 Chatbox WebUI를 통해 사용하는 방법을 안내합니다.
Ollama에서 사용할 수 있는 대표적인 AI 모델은 다음과 같습니다.
| 모델 | 개발사 | 특징 |
|---|---|---|
| Llama 3 | Meta | 자연어 처리 성능 우수 |
| Phi 3 | Microsoft Research | 추론 및 언어 이해 능력 강점 |
| Mistral | Mistral AI | 다양한 언어 작업에 최적화 |
| Gemma 2 | 자연어 처리 및 생성 작업에 강점 | |
| CodeGemma | 코드 생성 및 완성에 특화 |
0단계 — Gcube 계정 생성 및 로그인
0-1. 회원가입
https://gcube.ai 에 접속 후 우측 상단 "회원가입" 버튼을 클릭합니다. 이메일 인증을 완료하면 계정이 생성됩니다.
0-2. 로그인
회원가입 완료 후 동일한 페이지에서 로그인합니다.
0-3. 크레딧 확인
Gcube는 GPU 사용 시간에 따라 요금이 부과됩니다. 사용 전 대시보드에서 크레딧 잔액을 확인하세요.
요금 주의
워크로드는 배포 후부터 중지할 때까지 시간 단위로 과금됩니다. 사용 후 반드시 워크로드를 중지하세요. 중지 방법은 워크로드-워크로드 중지 항목을 참고하세요.
1단계 — Gcube 플랫폼에서 워크로드 등록하기
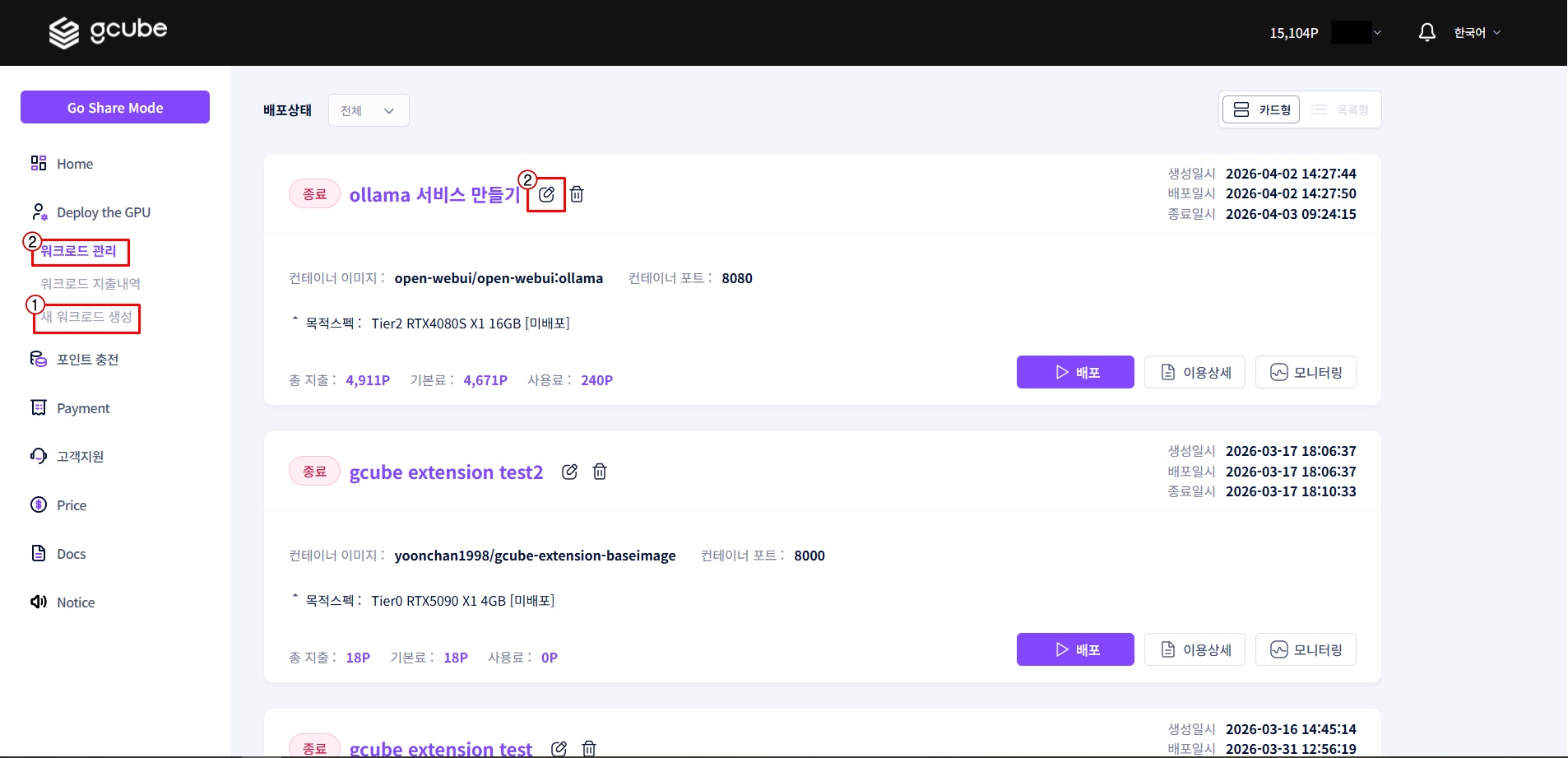
1-1. 워크로드 페이지 접속
https://gcube.ai/ko/demand/workload/list 에 접속합니다.
① 새 워크로드를 등록하거나, ② 기존에 등록된 워크로드를 선택해 수정합니다.
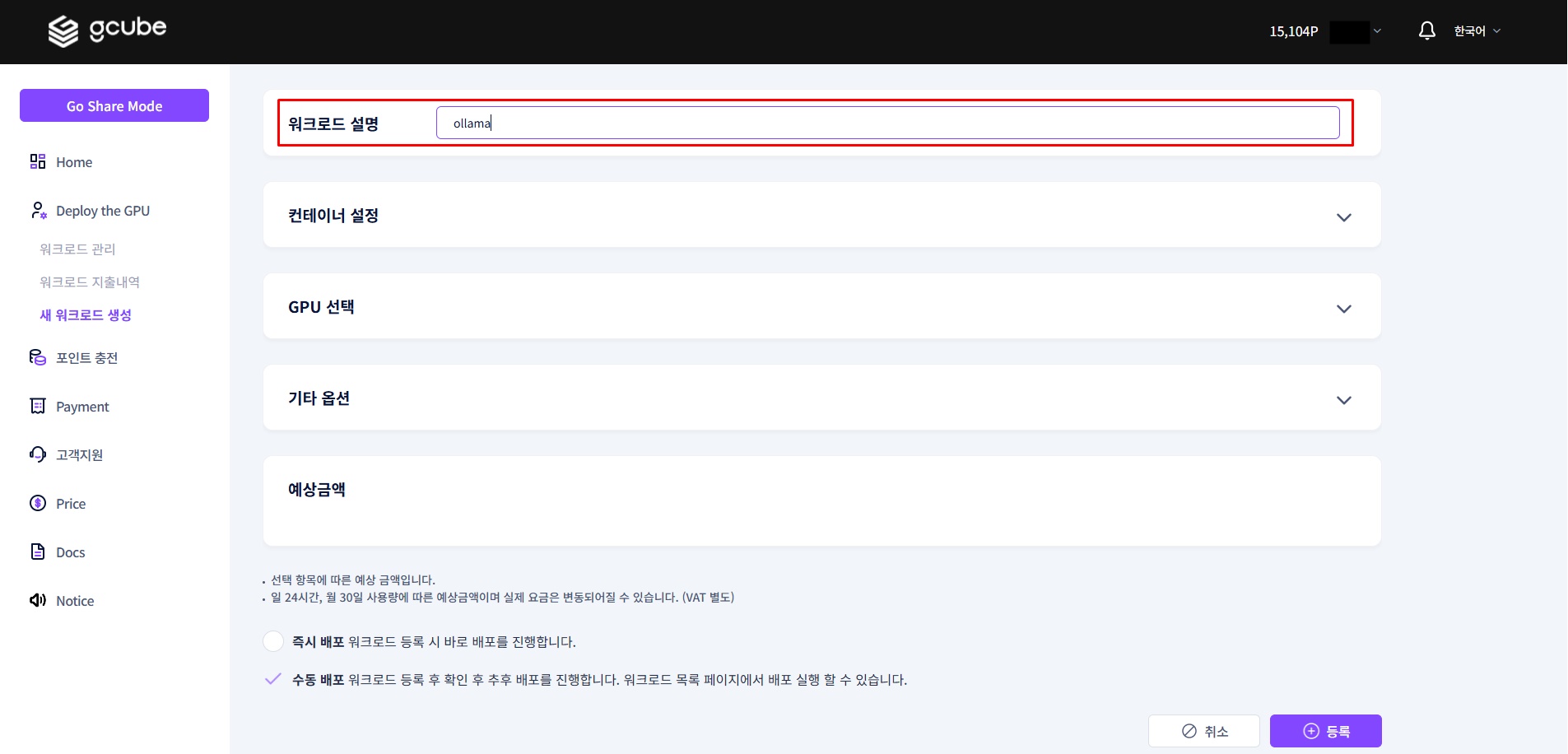
1-2. 설명 입력
워크로드 이름을 입력합니다.
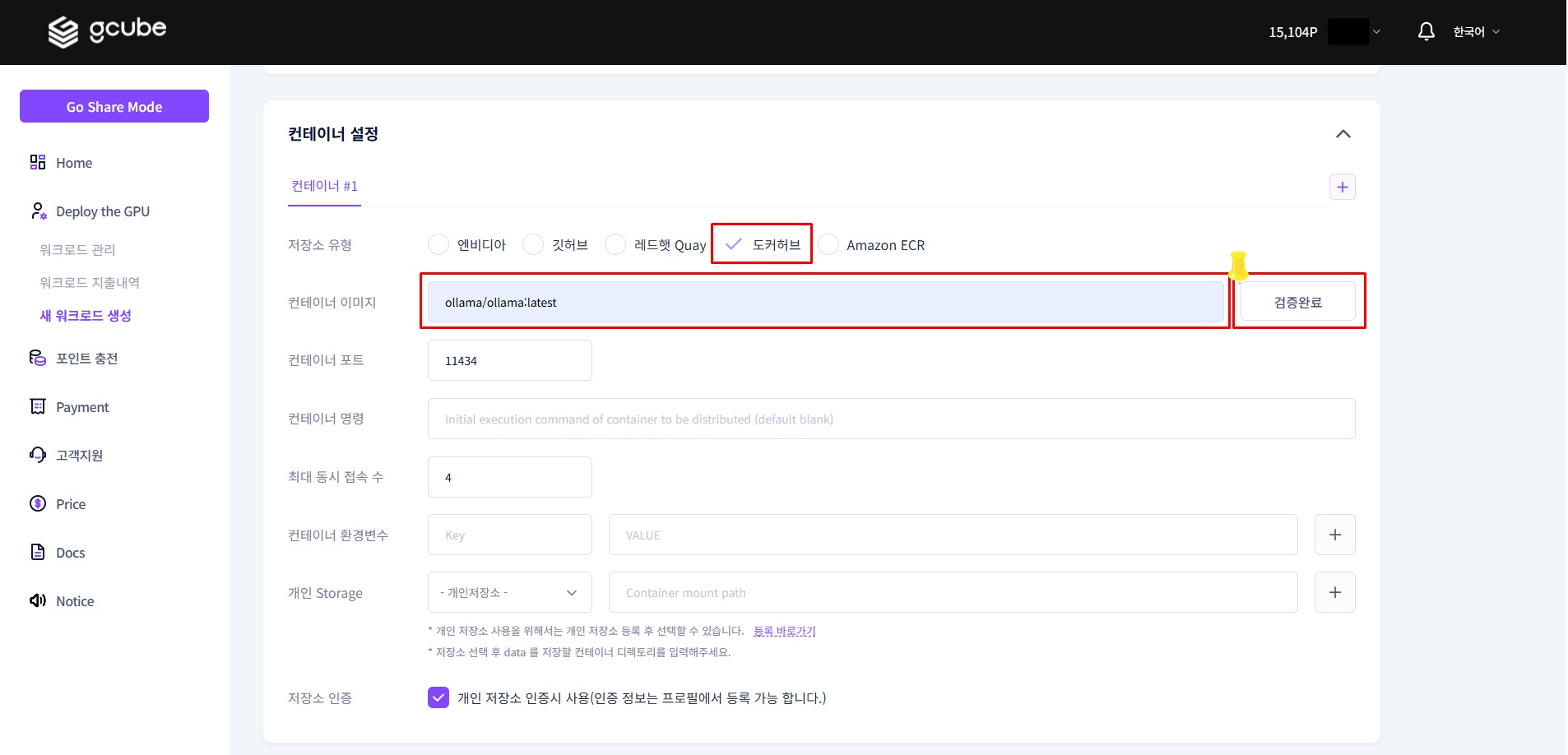
1-3. 컨테이너 설정
아래 내용을 순서대로 입력합니다.
| 항목 | 입력값 |
|---|---|
| 저장소 유형 | 도커허브 |
| 컨테이너 이미지 | ollama/ollama:latest |
| 컨테이너 포트 | 11434 |
💡 컨테이너 이미지 입력 후 옆의 이미지검증을 눌러 이미지 검증을 진행하세요. 검증이 완료되면 컨테이너 포트(
11434)가 자동으로 입력됩니다.공식 이미지 참조: https://hub.docker.com/r/ollama/ollama
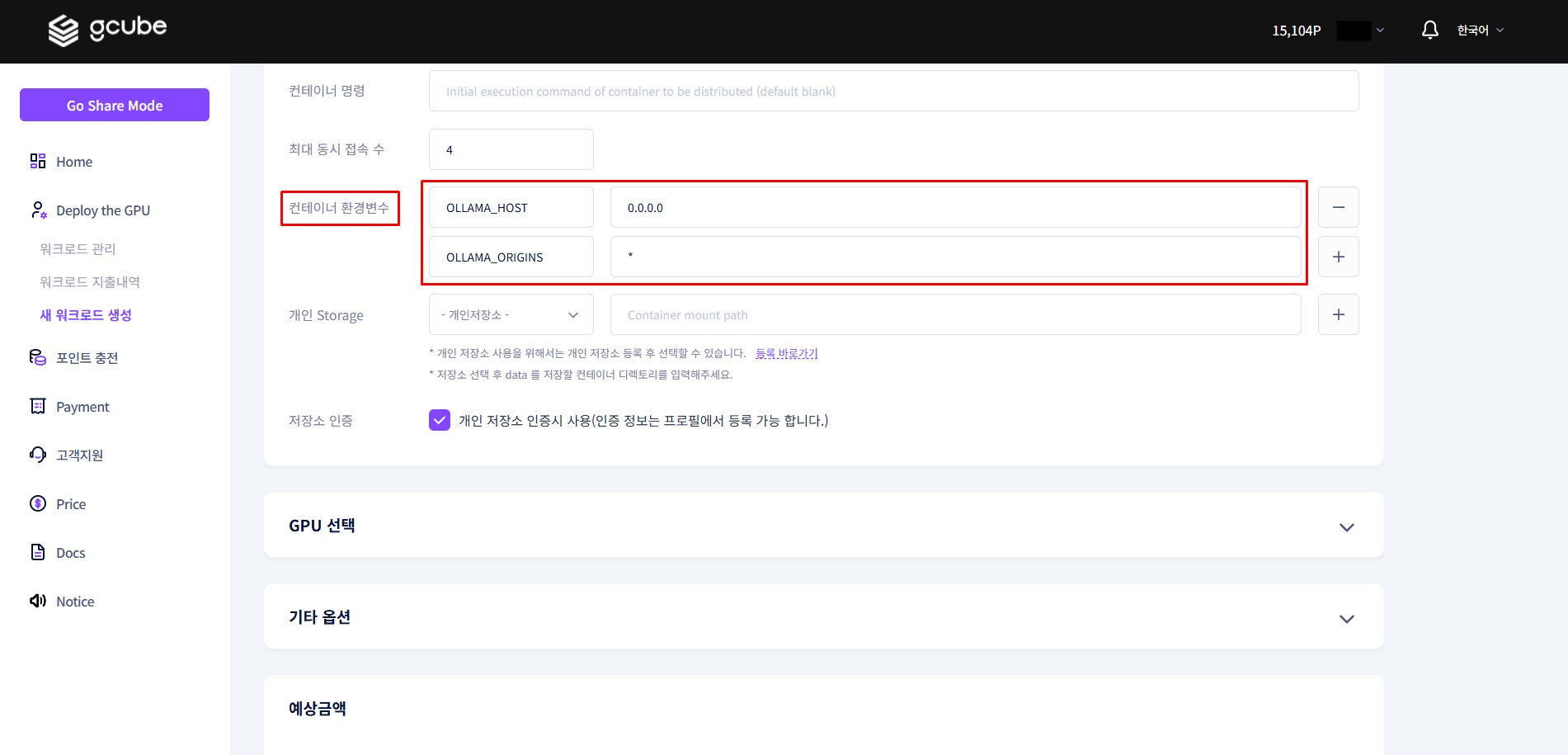
1-4. 환경 변수 설정
아래 두 가지 환경 변수를 반드시 입력합니다.
| Key | Value | 설명 |
|---|---|---|
OLLAMA_HOST |
0.0.0.0 |
모든 네트워크 인터페이스에서 접근 허용 (외부 WebUI 연결에 필요) |
OLLAMA_ORIGINS |
* |
CORS 제한을 해제하여 Chatbox 등 외부 클라이언트의 API 호출 허용 |
1-5. GPU 설정 선택
사용 목적에 맞는 GPU 스펙을 선택합니다.
| 티어 | 설명 |
|---|---|
| Tier 1 | 고성능 |
| Tier 2 | 고신뢰성 |
| Tier 3 | 개인 사용자 |
모델과 GPU 선택 기준
모델 크기(파라미터 수)에 따라 필요한 GPU 메모리가 달라집니다.
| 모델 태그 | 파라미터 | 권장 GPU 메모리 |
|-----------|----------|----------------|
| deepseek-r1:1.5b | 1.5B | 4GB 이상 |
| deepseek-r1:7b | 7B | 8GB 이상 |
| **deepseek-r1:8b** | **8B** | **8GB 이상** |
| deepseek-r1:14b | 14B | 16GB 이상 |
이 가이드에서는 성능과 속도의 균형이 좋은 **`deepseek-r1:8b`** 와 **Tier 3 — RTX 4070 (12GB)** 조합을 기준으로 합니다.
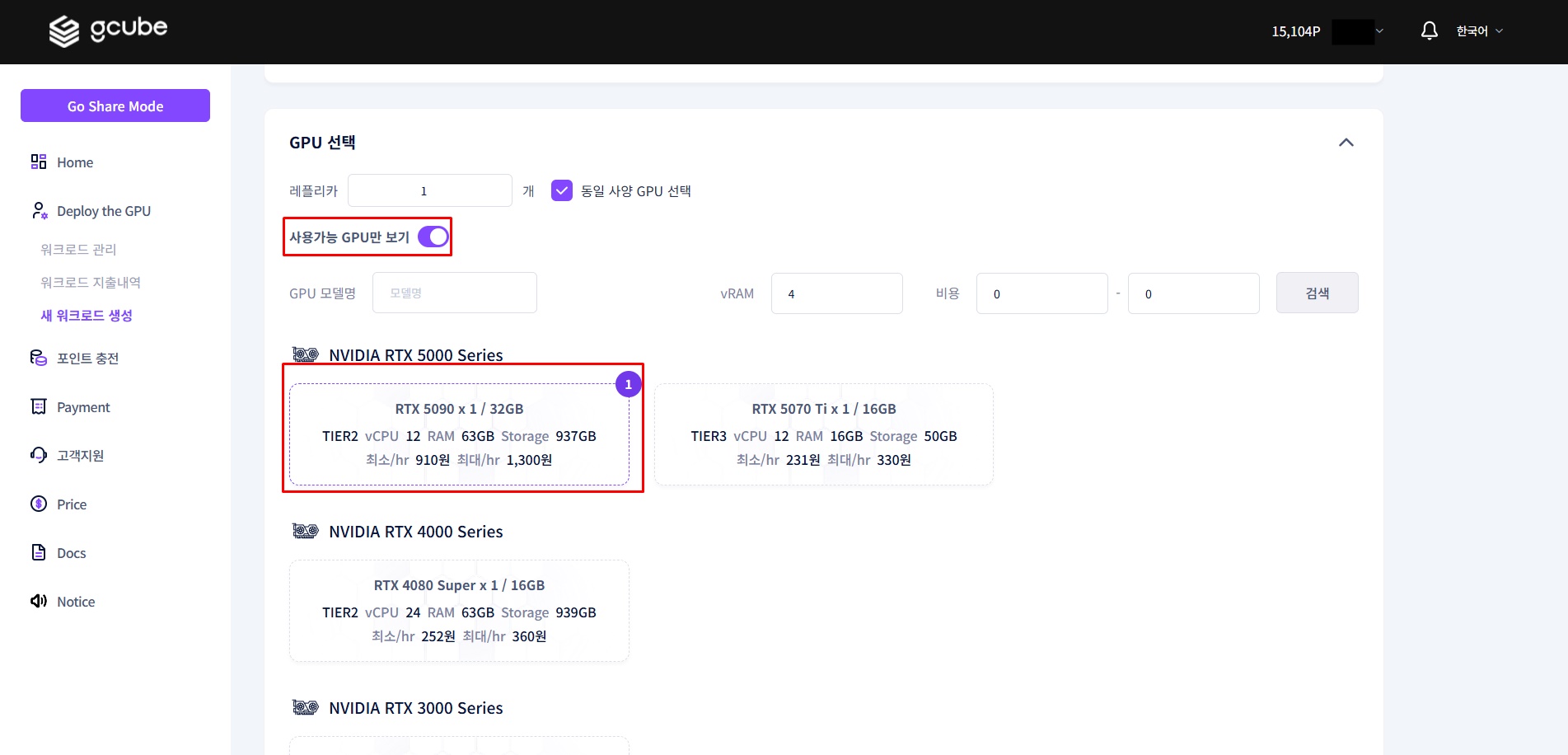
1-6. 최종 확인 및 배포
💡 Step 4. 기타 옵션 설정 워크로드 부가 옵션을 설정하는 단계입니다.
특별한 요구 사항이 없다면 기본값 그대로 두고 다음 단계를 눌러 진행하면 됩니다.
선택한 스펙의 시간당 예상 금액을 확인합니다.
요금 안내
표시되는 금액은 시간당 최대 요금입니다. 실제 사용 시간에 비례해 청구되므로, 테스트 후에는 워크로드를 반드시 중지하세요.
내용이 맞으면 '즉시배포' 를 선택 후, ‘등록’으로 배포를 완료합니다.
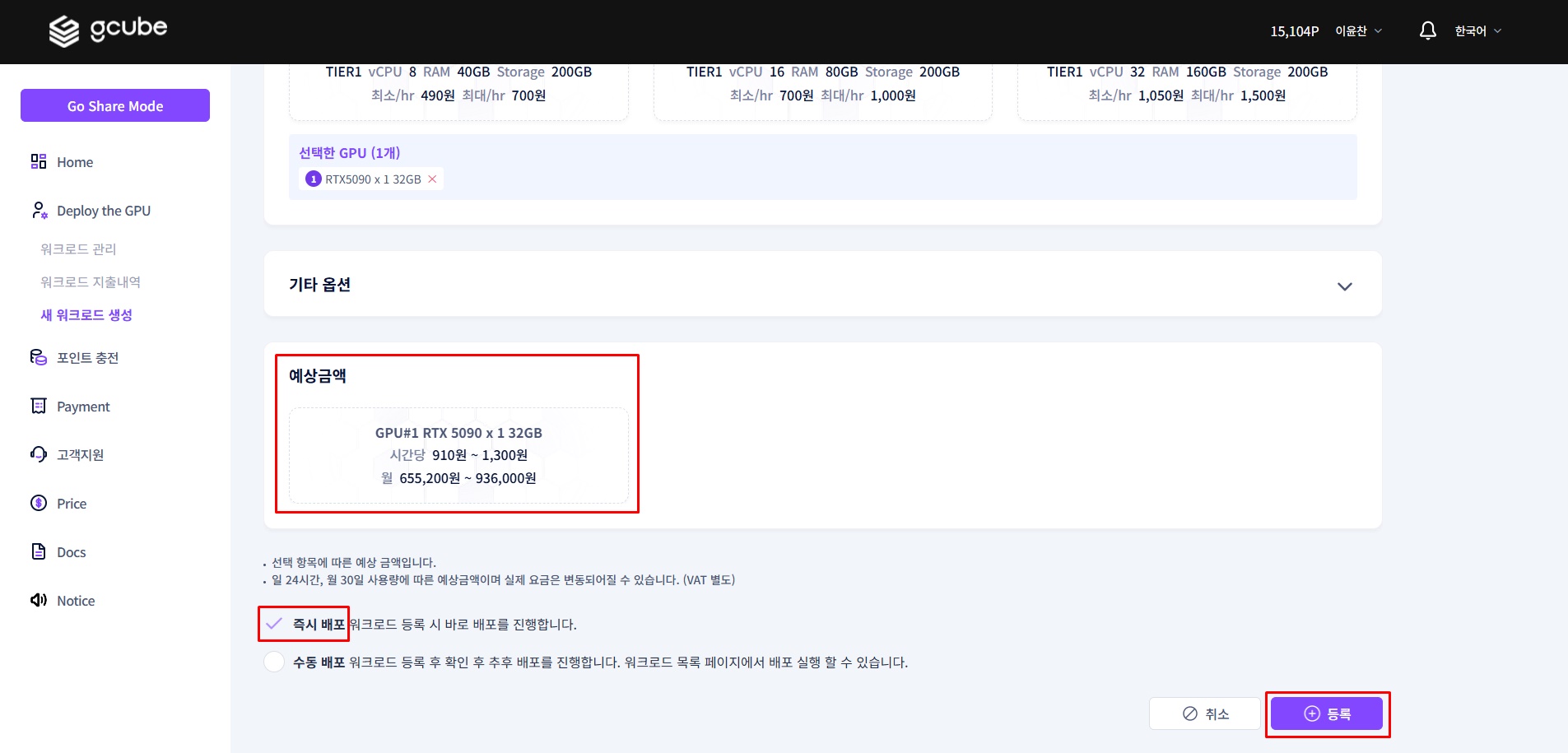
2단계 — DeepSeek 모델 실행하기
2-1. 생성된 워크로드 확인
워크로드 페이지에서 방금 만든 워크로드 이름을 클릭하면 세부 정보로 진입합니다.
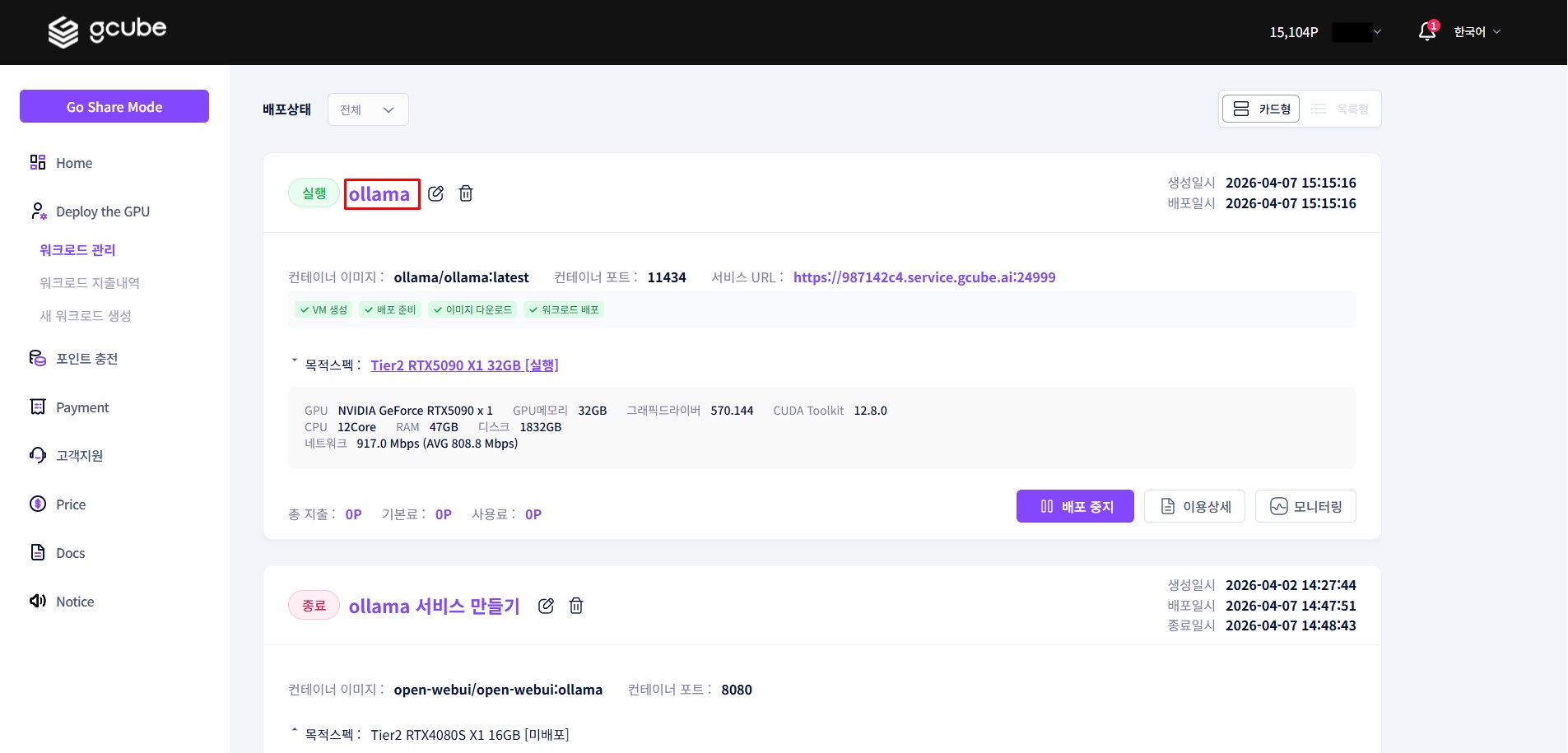
세부 정보 화면에서 확인할 수 있는 주요 항목은 다음과 같습니다.
- 상세 내용: 워크로드 번호, 상태, 워크로드 정보 등
- HTTP 서비스: 서비스 URL 접속
- 노드 정보: GPU 정보, 컨테이너 로그, 터미널, SSH 접속 등
- 기타 설정: 프록시, 라우팅, CUDA 정보 등
- 사용 비용: 사용 비용 정보
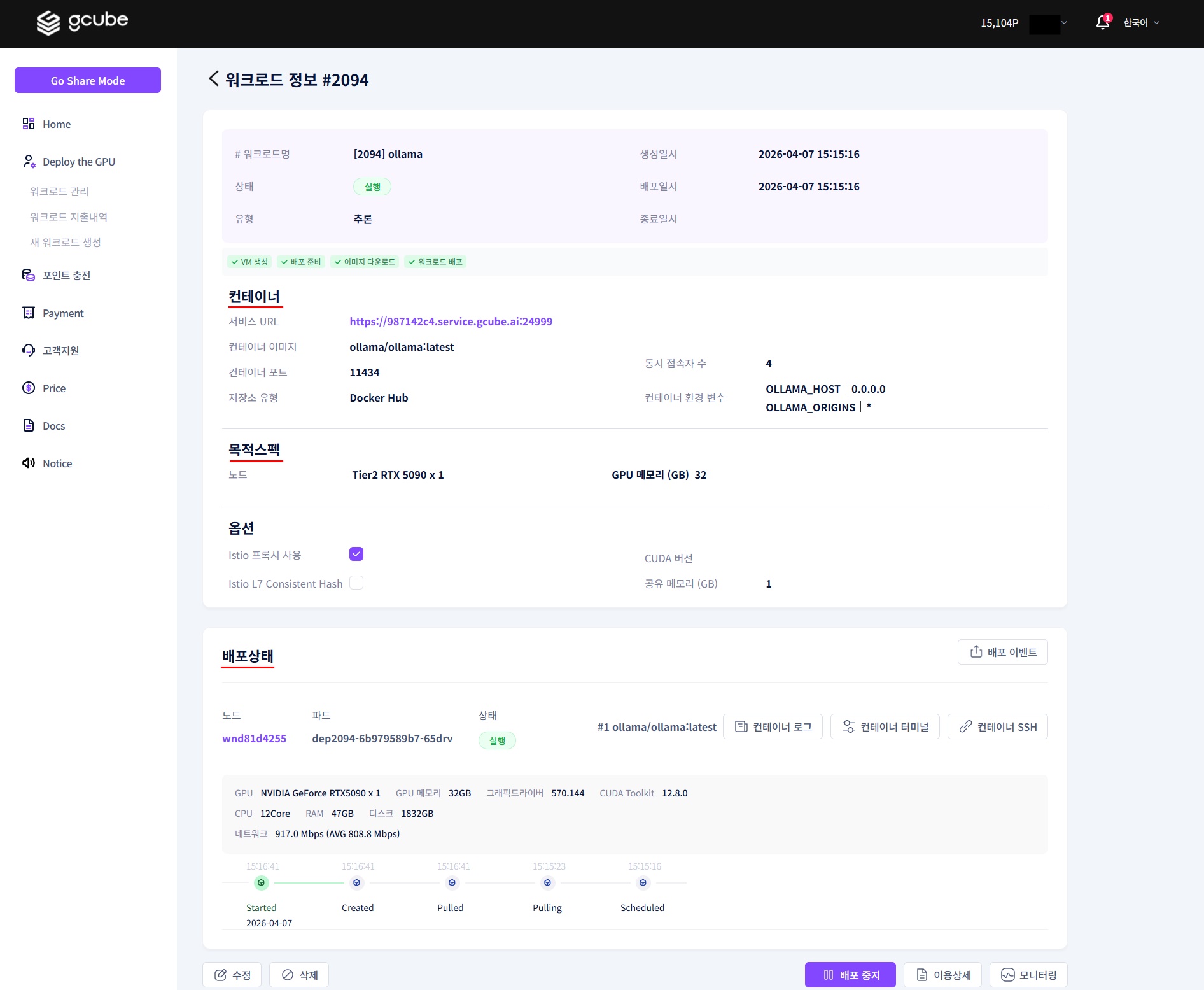
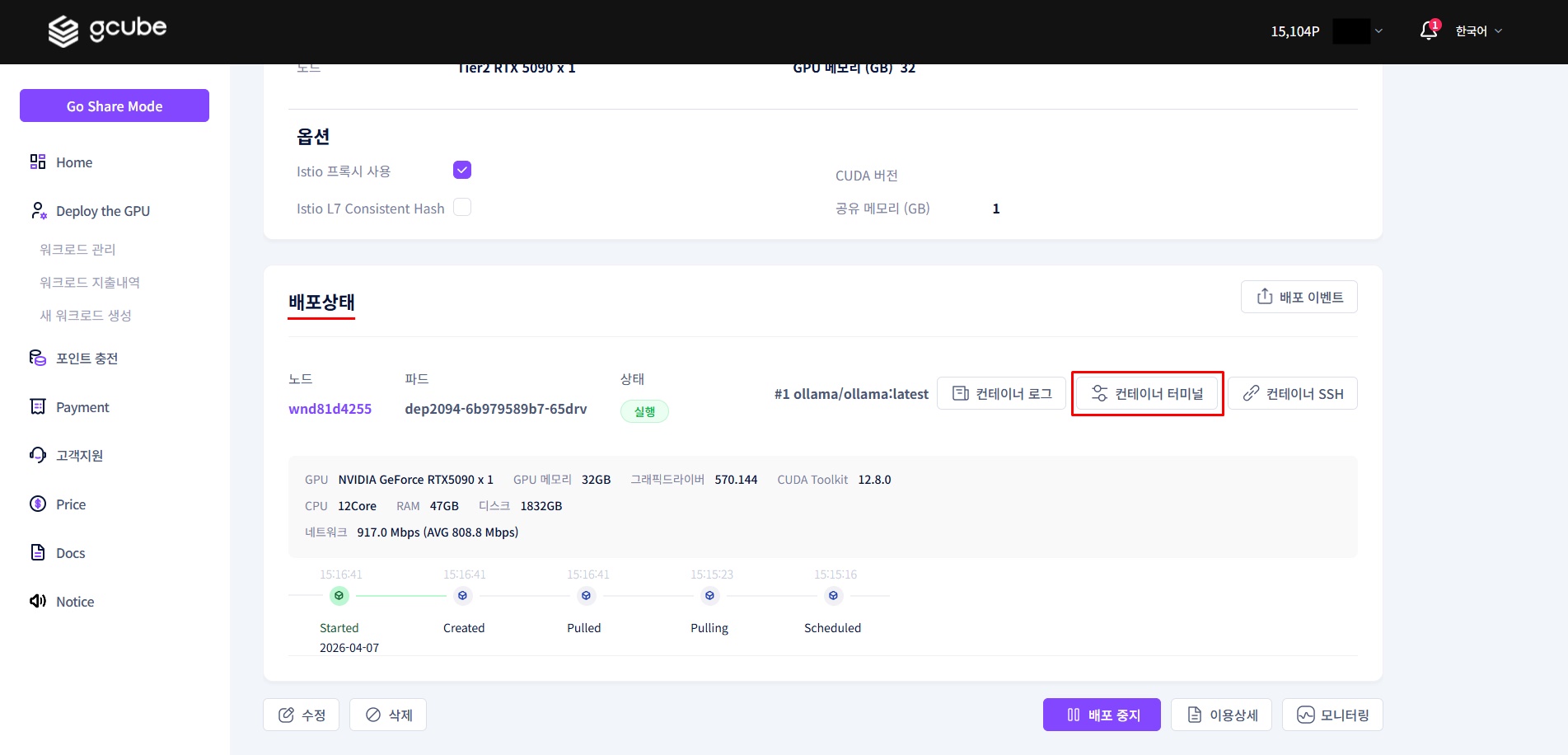
2-2. 컨테이너 터미널 실행
파드 상태가 '실행' 으로 표시되면, 컨테이너 터미널을 클릭해 실행합니다.
💡 배포 직후에는 파드가 준비되는 데 수 분이 걸릴 수 있습니다. '실행' 상태가 될 때까지 기다린 후 진행하세요.
2-3. DeepSeek 모델 다운로드 및 실행
터미널에 아래 명령어를 입력합니다. 모델 크기는 약 4.7GB이며, 다운로드에 수 분이 소요될 수 있습니다.

다운로드가 완료되면 모델이 자동으로 실행됩니다.
3단계 — Chatbox WebUI에서 DeepSeek 연결하기
Chatbox는 별도 설치 없이 브라우저에서 바로 사용하는 WebUI입니다. Gcube 워크로드의 서비스 URL을 API 호스트로 입력하면 실행 중인 DeepSeek 모델에 연결됩니다.
https://web.chatboxai.app/copilots 에 접속합니다.
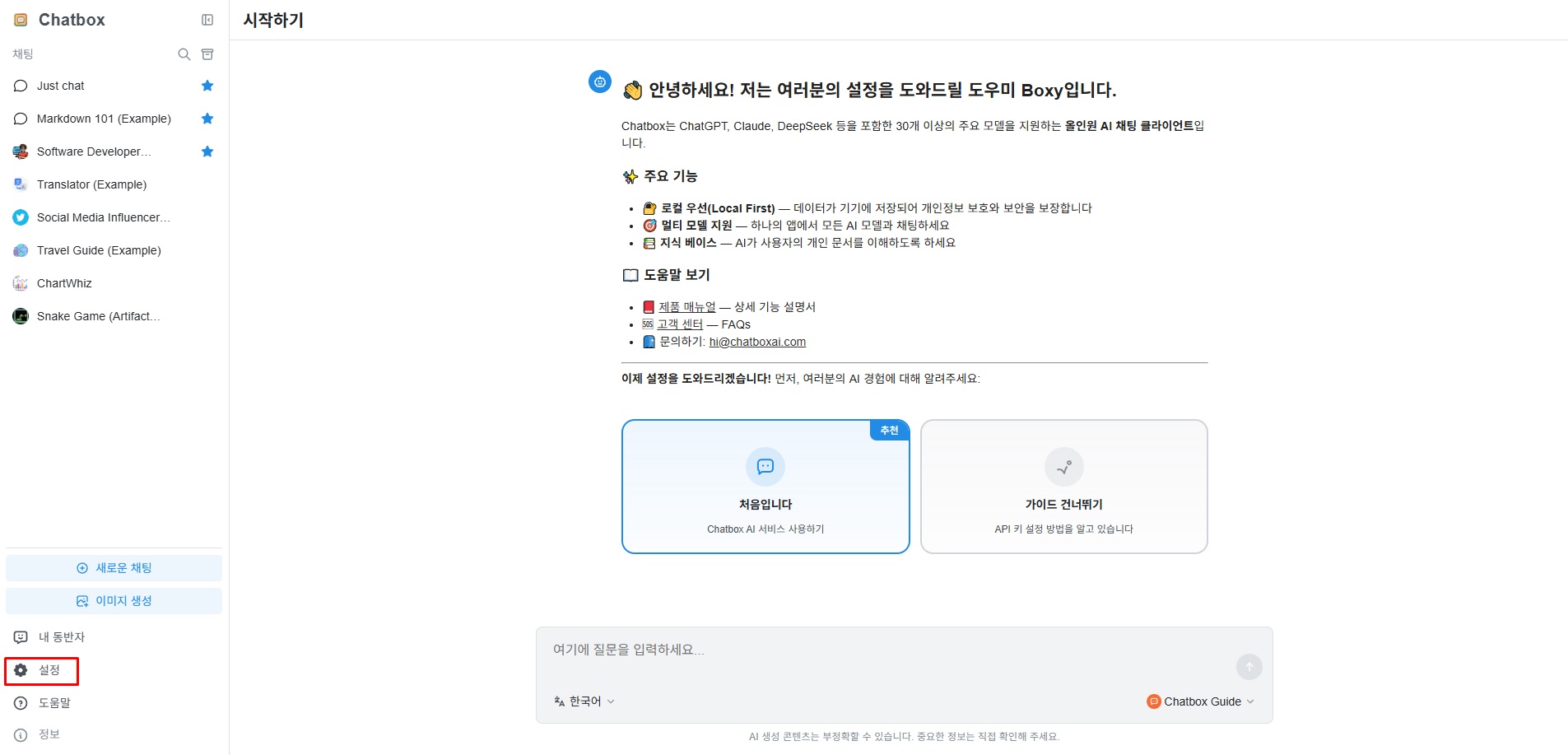
3-1. gcube API 설정
Chatbox에 처음 접속하면 아래와 같은 화면이 나타납니다. 좌측 메뉴 바 하단에 위치한 "설정" 버튼을 클릭합니다.
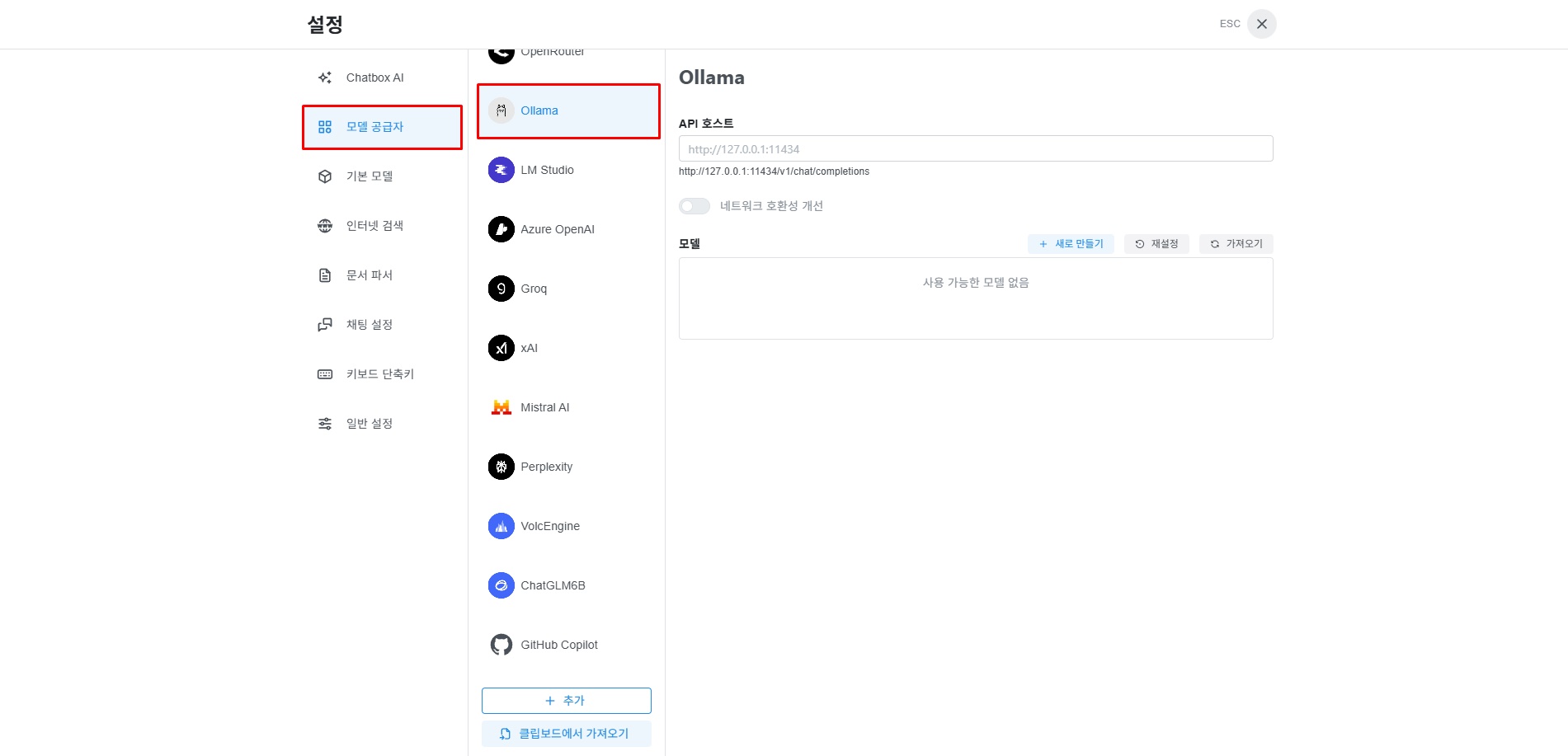
3-2. Ollama API 선택
설정 메뉴들 중 “모델 공급자”를 클릭합니다. 다음으로 AI 모델들 중 “Ollama”를 선택합니다.
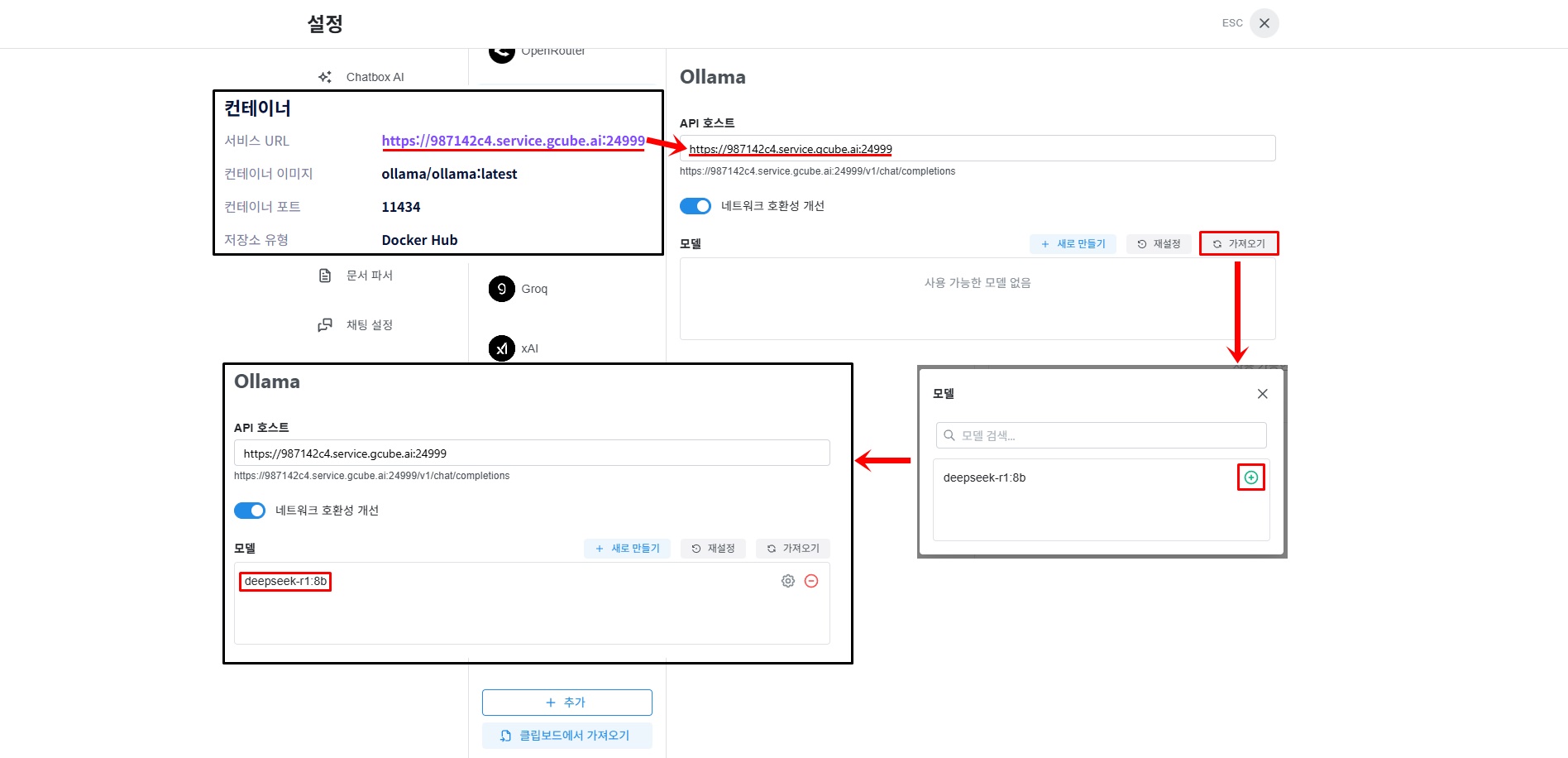
3-3. 서비스 URL 및 모델 입력
gcube 워크로드 세부 정보 화면 개요 탭에서 "서비스 URL" 을 복사합니다.
💡 서비스 URL은 워크로드 세부 정보 화면 상단 개요 섹션에 위치합니다.
https://xxxxxxxx.gcube.ai형태입니다.
gcube 워크로드 정보 중 “서비스 URL”을 복사한 후, API 호스트 입력란에 붙여 넣습니다. 모델 항목의 “가져오기”를 클릭하면 팝업창이 표시되며 다운로드한 모델이 표시됩니다. 사용하고자 하는 모델 옆 “+” 표시를 눌러 추가한 후, 팝업창을 닫게되면 해당 모델이 추가됩니다.
3-4. 사용 시작
“ESC” 버튼을 클릭하여 메인 화면으로 돌아갑니다.
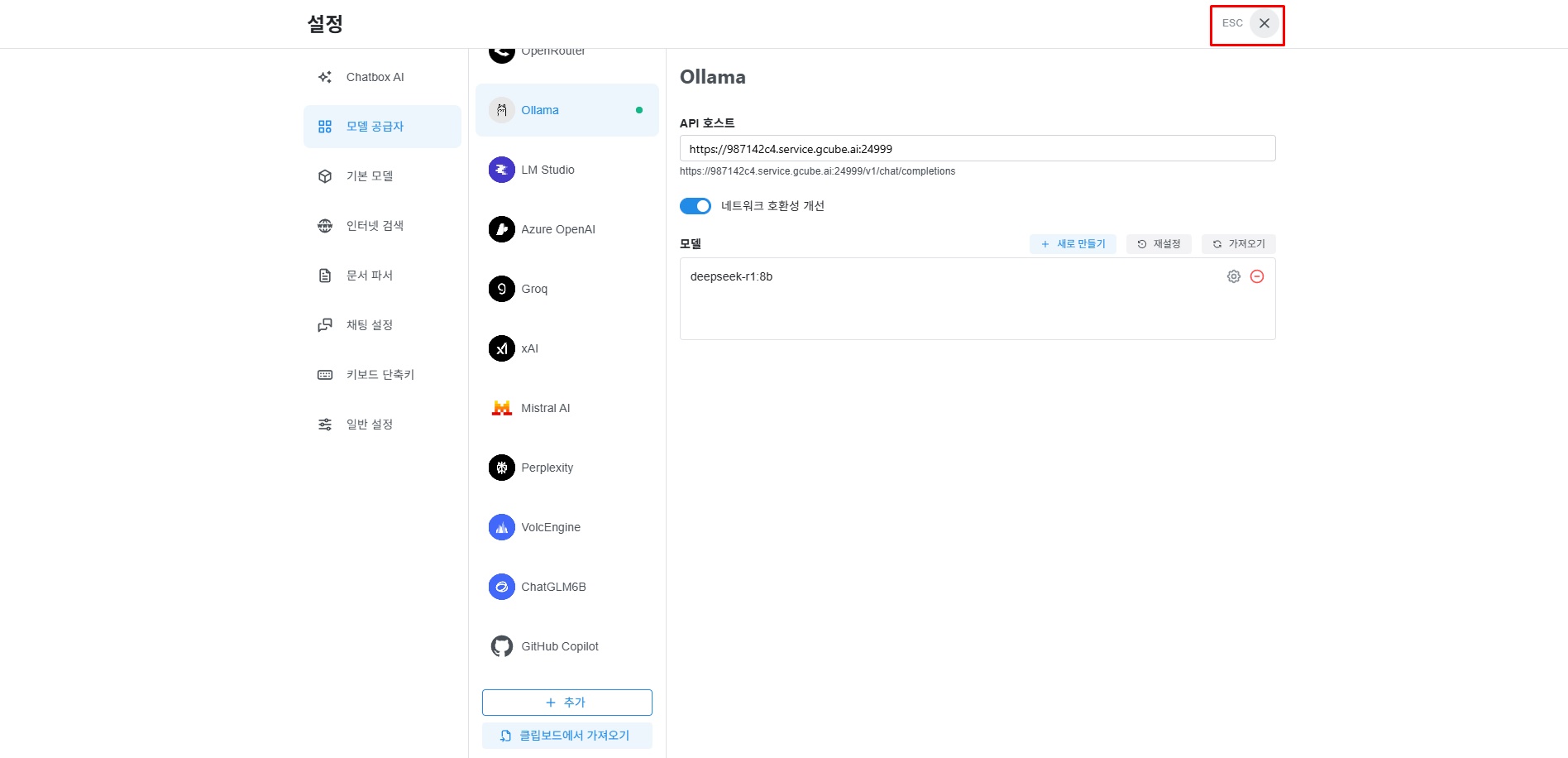
메인 화면 좌측 메뉴 중 “새로운 채팅”을 클릭합니다.
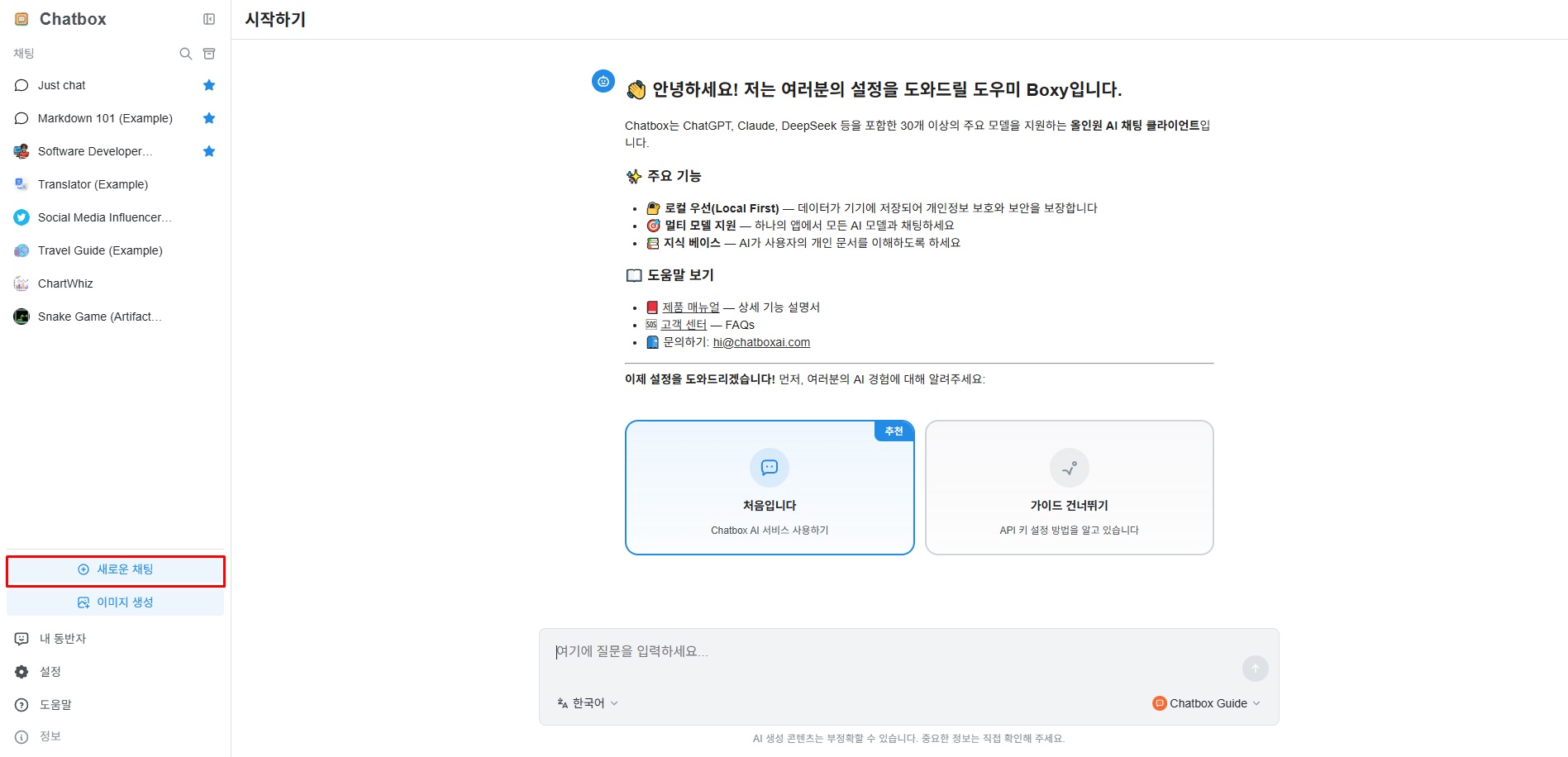
대화 입력란 하단에 위치한 ①“모델 선택”을 클릭한 후, ②다운로드 받은 모델을 클릭합니다.
이후 자유롭게 사용하시면 됩니다.
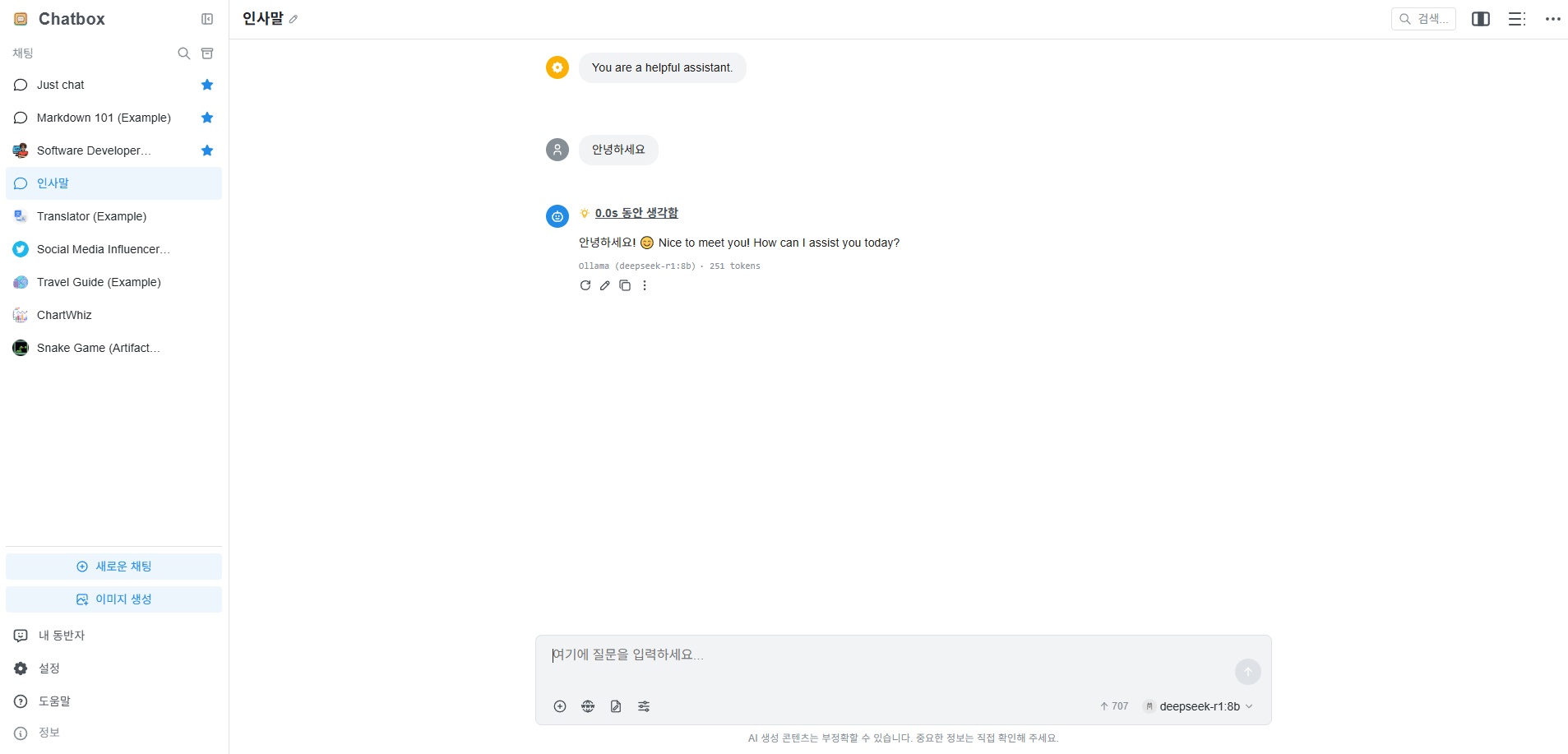
사용 예시
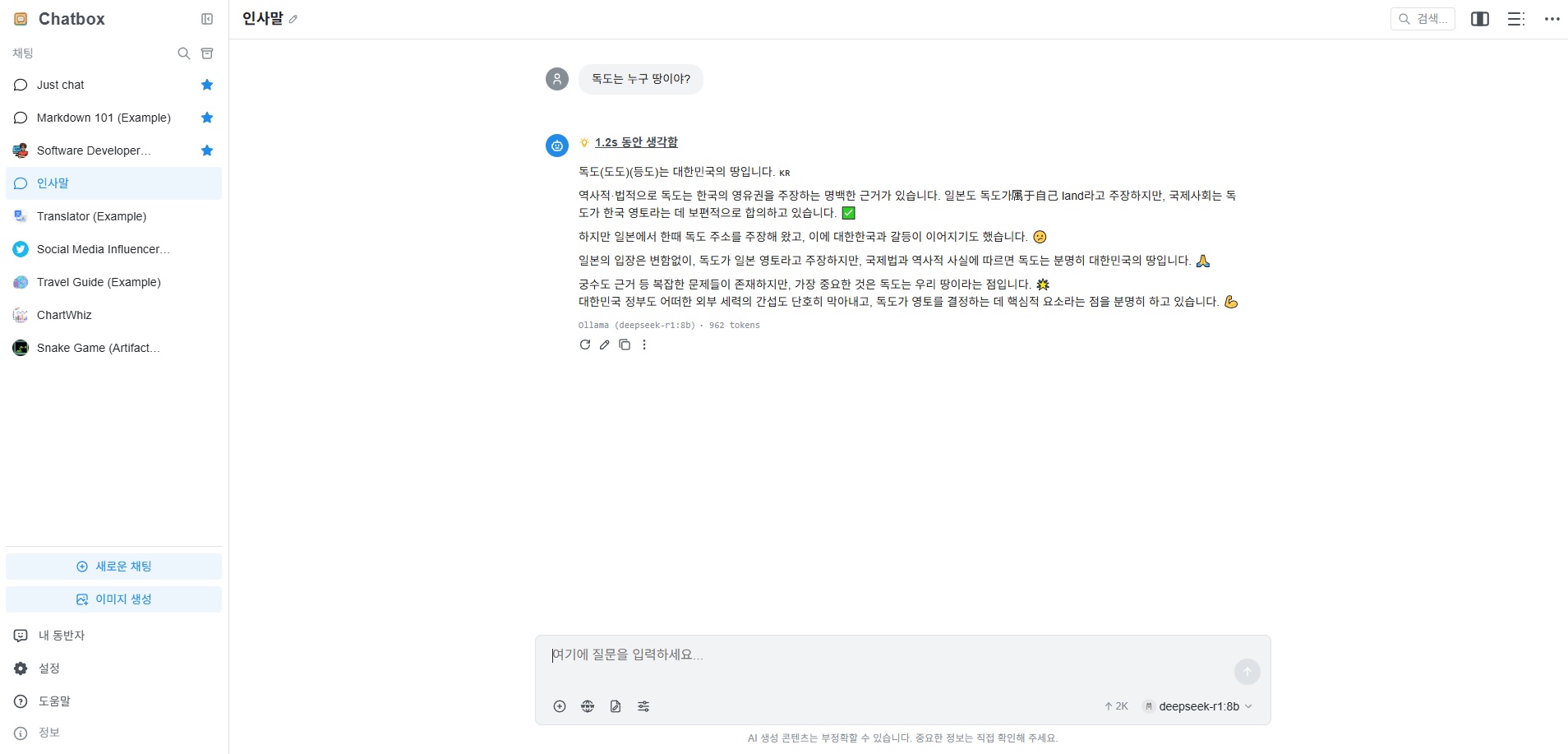
Q: 독도는 누구 땅이야?
4단계 — 워크로드 중지 및 삭제
반드시 확인하세요
워크로드를 중지하지 않으면 사용하지 않는 동안에도 요금이 계속 부과됩니다.
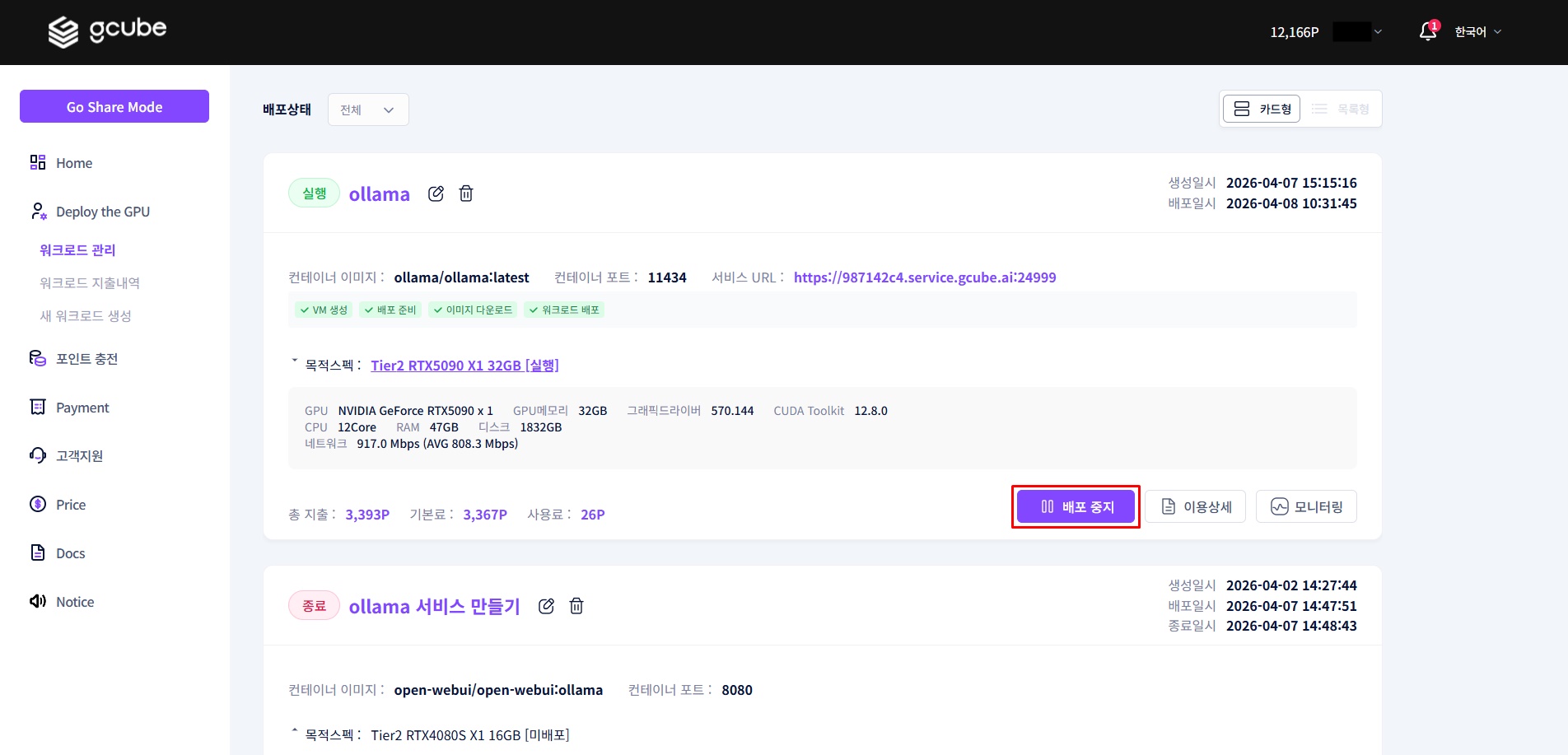
4-1. 워크로드 중지
워크로드 관리에서 배포중인 워크로드의 "배포 중지" 버튼을 클릭합니다. 워크로드 상태가 '배포 중지'로 바뀌면 과금이 멈춥니다.
💡 중지 후 재시작 시 모델을 다시 다운로드해야 할 수 있습니다. 자주 사용한다면 중지보다 사용 중 유지 후 삭제하는 방식을 고려하세요.
4-2. 워크로드 삭제
더 이상 사용하지 않을 경우 워크로드 목록에서 해당 워크로드를 삭제합니다. 삭제 시 컨테이너 내부 데이터(다운로드된 모델 포함)가 모두 제거됩니다.
문제 해결 (FAQ)
Q. 파드 상태가 '실행'이 되지 않아요.
배포 직후에는 준비 시간이 필요합니다. 수 분 후 페이지를 새로고침해 보세요. 그래도 해결되지 않으면 배포상태 탭의 컨테이너 로그를 확인하세요.
Q. 모델 다운로드가 너무 느려요.
DeepSeek-r1:8b 모델은 약 4.7GB입니다. 네트워크 환경에 따라 시간이 걸릴 수 있으며, 터미널을 닫지 말고 완료될 때까지 기다리세요.
Q. Chatbox에서 모델이 표시되지 않아요.
아래 항목을 순서대로 확인하세요.
- 워크로드 파드 상태가 '실행' 중인지 확인
- API 호스트에 입력한 서비스 URL이 정확한지 확인 (
https://포함 여부) - 모델명이
deepseek-r1:8b로 정확히 입력되었는지 확인
Q. 워크로드를 중지했다가 다시 시작하면 모델을 다시 설치해야 하나요?
컨테이너를 중지(Stop) 했다가 재시작하면 기존 데이터가 유지되지 않을 수 있습니다. 삭제(Delete) 한 경우에는 반드시 모델을 다시 다운로드해야 합니다.